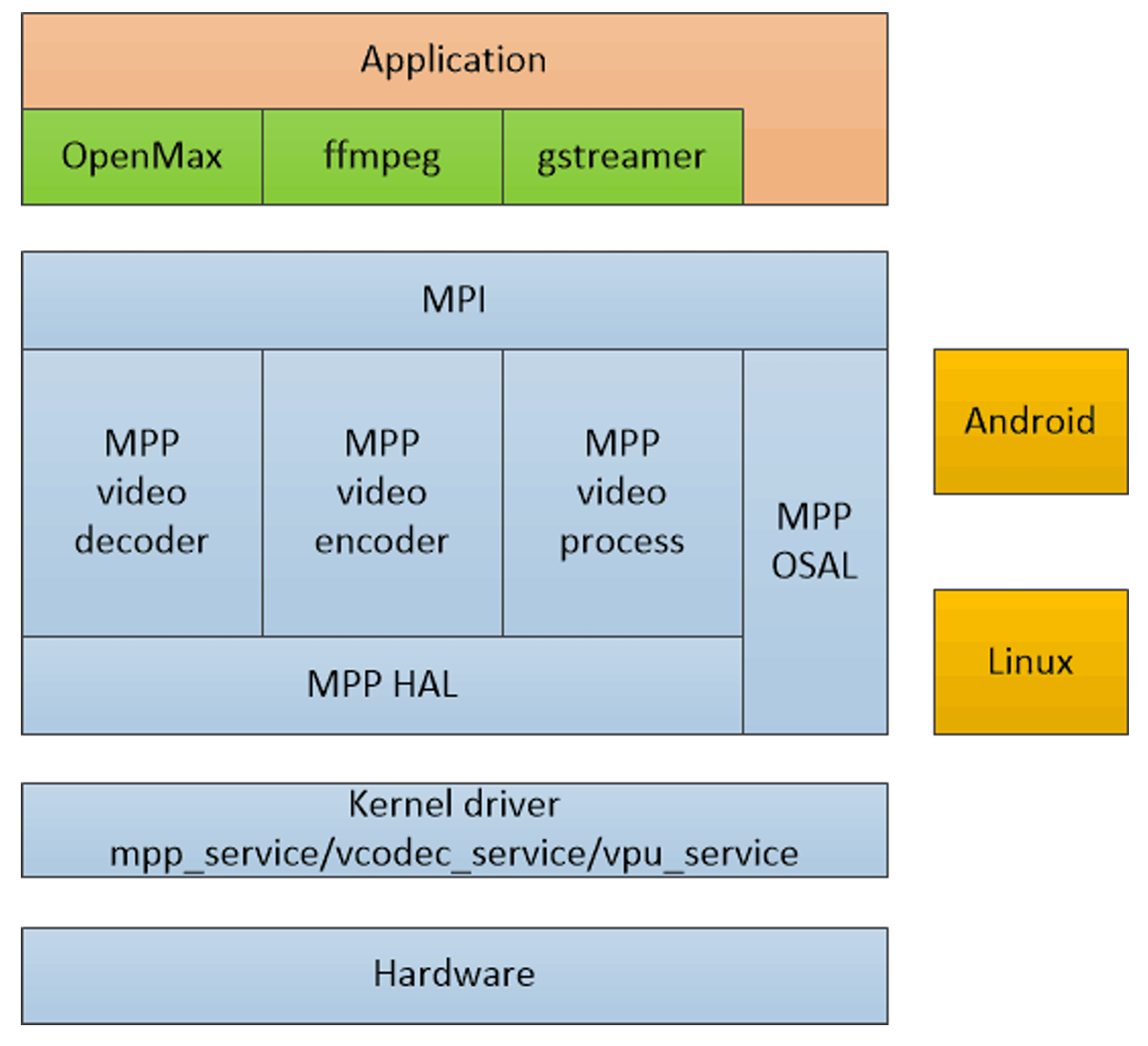
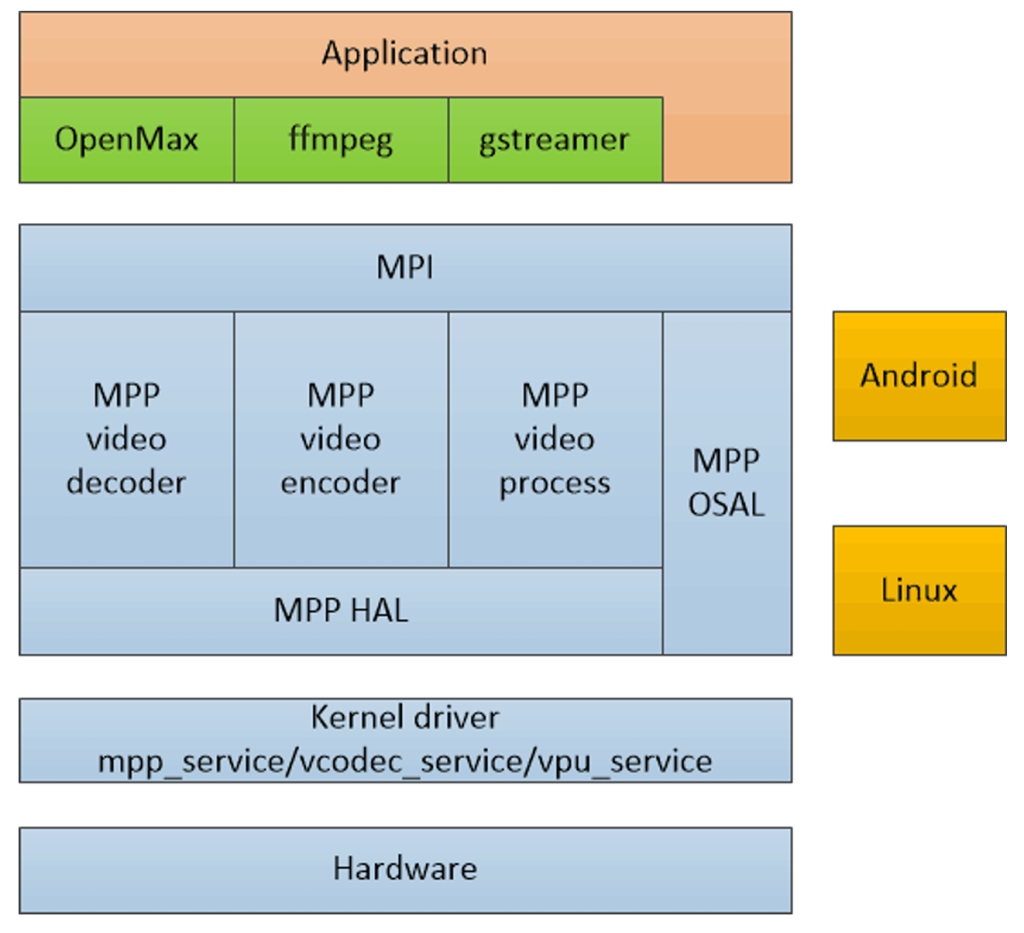
瑞芯微mpp编码
本篇文章将详细讲解瑞芯微mpp的编码使用,从编译开始到API解析到源码全部开放,让大家能够对瑞芯微mpp编码有一定的了解,具体深入可以查看瑞芯微的官方手册
笔者使用的芯片是RK3576,但是对应瑞芯微支持mpp的芯片的思想以及调用API都是一样的
mpp编译
mpp交叉编译
环境配置
更改交叉编译工具链
在获取到瑞芯微的mpp代码仓库后,进入
build/linux/aarch64/目录下rk3576是arm64位,如果是32位进入
build/linux/arm/这里使用的是板厂给的SDK,可以根据自己的板子向厂商要SDK,也可以直接去github上获取瑞芯微官方SDK
修改
arm.linux.cross.cmake文件里面的交叉编译工具链,改为自己的交叉编译工具链路径xxxxxxxxxxubuntu@ubuntu-2204:~/100ask-rk3576_SDK/external/mpp/build/linux/aarch64$ cat arm.linux.cross.cmakecmake_minimum_required( VERSION 2.6.3 )SET(CMAKE_SYSTEM_NAME Linux)SET(CMAKE_C_COMPILER "/home/ubuntu/100ask-rk3576_SDK/prebuilts/gcc/linux-x86/aarch64/gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu-gcc")SET(CMAKE_CXX_COMPILER "/home/ubuntu/100ask-rk3576_SDK/prebuilts/gcc/linux-x86/aarch64/gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu-g++")#SET(CMAKE_SYSTEM_PROCESSOR "armv7-a")SET(CMAKE_SYSTEM_PROCESSOR "armv8-a")add_definitions(-fPIC)add_definitions(-DARMLINUX)add_definitions(-Dlinux)CMake && make
运行make-Makefiles.bash脚本,通过cmake 生成 Makefile ,最后运行
make进行编译。安装依赖库
使用
sudo make install命令可以把mpp的相关头文件库文件安装在/usr/local/include/rockchip和/usr/local/lib,如果不想安装在默认目录可以执行命令:xxxxxxxxxxmake install DESTDIR= 想要放置的路径
代码编译
情况:我在~/100ask-rk3576_SDK/external/mpp/test路径下写了一个新的mpp编解码程序,并且只想编译这个程序做一个测试
使用的是命令:
xxxxxxxxxx/home/ubuntu/100ask-rk3576_SDK/prebuilts/gcc/linux-x86/aarch64/gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu-g++ \ -I/usr/local/include/rockchip \ -I../inc \ -I../osal/inc \ -I../utils \ -I. \ my_test.cpp \ -L/usr/local/lib \ -lrockchip_mpp -lpthread -ldl \ -o my_test各 -I 路径说明:
-I/usr/local/include/rockchip | 公共 API:rk_mpi.h,rk_type.h |
-I../inc | MPP 核心头文件(如mpp_frame.h等,虽然部分已安装,但保持一致) |
-I../osal/inc | OS 抽象层头文件 |
-I../utils | 关键!包含 mpp_env.h, mpp_mem.h 等 |
-I. | 当前目录,用于mpi_enc_utils.h,utils.h(如果它们在test/目录) |
rk3576本地编译
为了方便并且我的RK3576配置足够强大(12+128),我也在rk3576本地编译了mpp库
1.安装基础依赖:
xxxxxxxxxxsudo apt updatesudo apt install git cmake2.获取MPP库,这里就是官方的SDK
xxxxxxxxxxgit clone https://github.com/rockchip-linux/mpp.git3.编译
xxxxxxxxxxcd mpp/build/linux/aarch64/./make-Makefiles.bashmakesudo make install想要编译自己写的mpp程序,也需要向上面交叉编译一样指定库目录链接目录
过程中遇到的问题就是我根据上面的命令进行编译会报错一大堆mpp的函数未定义,最后将动态链接参数命令放在输出名后面才成功,个人认为是因为gcc的依赖关系是从左到右解析的,所以如果把my_test.cpp -o my_test放在最后那么出现在代码段中的外部链接符号不能被解析,所以要把-lrockchip_mpp -lpthread -ldl放在最后面
但是为何交叉编译就可以动态链接参数在前面?还不知道
最终Makefile模板:
xxxxxxxxxxPUBLIC_API_DIR = /usr/local/include/rockchipCORE_API_DIR = /home/kidwjb/sourceCode/videoSourceCode/mppSourceCode/mpp/inc/OS_API_DIR = /home/kidwjb/sourceCode/videoSourceCode/mppSourceCode/mpp/osal/inc/UTILS_DIR = /home/kidwjb/sourceCode/videoSourceCode/mppSourceCode/mpp/utils/LINK_DIR = /usr/local/libPARAM_MPP = rockchip_mppPARAM_PTHREAD = pthreadPARAM_DL = dlall : g++ -I $(PUBLIC_API_DIR) \ -I $(CORE_API_DIR) \ -I $(OS_API_DIR) \ -I $(UTILS_DIR) \ -L $(LINK_DIR) \ my_test.cpp -o my_test \ -l$(PARAM_MPP) \ -l$(PARAM_PTHREAD) \ -l$(PARAM_DL).PHONY: all
vscode中编写mpp
在使用vscode进行开发时遇到问题就是无法识别头文件,哪怕我已经make install了但是也不行,最终查看到/usr/local/include/rockchip/中确实有mpp的公共头文件,但是我在源码中错误的使用了#include "rk_mpi.h"而不是使用<>来包含头文件,正确做法是
xxxxxxxxxx对于并不是公共头文件而是源码内的一些官方例程头文件,则需要进一步配置,在项目的根目录创建一个.vscode文件夹,然后创建一个配置json文件c_cpp_properties.json在里面写入
xxxxxxxxxx{ "configurations": [ { "name": "Linux", "includePath": [ "${workspaceFolder}/**", "/usr/local/include/rockchip", "/home/kidwjb/sourceCode/videoSourceCode/mppSourceCode/mpp/osal/inc", "/home/kidwjb/sourceCode/videoSourceCode/mppSourceCode/mpp/utils" ], "defines": [], "compilerPath": "/usr/bin/gcc", "cStandard": "c11", "cppStandard": "c++17", "intelliSenseMode": "linux-gcc-arm64" } ], "version": 4}注意includePath中要写入的是实际的头文件所在的一层目录而不是只是mpp源码顶层目录
mpp开发
说明:以下都是基于瑞芯微的mpp
链接utils
在代码编写中要对输入文件进行读取,使用的是utils.c里面的read_image函数
xxxxxxxxxxMPP_RET read_image(RK_U8 *buf, FILE *fp, RK_U32 width, RK_U32 height, RK_U32 hor_stride, RK_U32 ver_stride, MppFrameFormat fmt)utils.c(以及 utils.h)是 Rockchip MPP SDK 中的“示例工具代码”,通常不被编译进动态库(如 librockchip_mpp.so),而是作为 测试程序的源码组件,需要手动编译链接。
librockchip_mpp.so 包含什么?
- MPP 核心 API:
mpp_create,mpp_init,mpp_buffer_get,rk_mpi.h中声明的接口等。 - 编码器/解码器硬件抽象层(HAL)
- 内存管理、任务调度等底层逻辑
使用命令首先将
utils.c编译为可重入文件(注意是使用gcc)我当前的路径是在test路径之下
xxxxxxxxxx/home/ubuntu/100ask-rk3576_SDK/prebuilts/gcc/linux-x86/aarch64/gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu-gcc -I../inc -I../osal/inc -I../utils -c ../utils/utils.c -o utils.o再编译自己的源文件
xxxxxxxxxx/home/ubuntu/100ask-rk3576_SDK/prebuilts/gcc/linux-x86/aarch64/gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu-g++ \-I/usr/local/include/rockchip \-I../inc \-I../osal/inc \-I../utils \-I. \-c \my_test.cpp -o my_test.o最后将两个可重入文件链接起来
xxxxxxxxxx/home/ubuntu/100ask-rk3576_SDK/prebuilts/gcc/linux-x86/aarch64/gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnu/bin/aarch64-none-linux-gnu-g++ my_test.o utils.o -L/usr/local/lib -lrockchip_mpp -lpthread -ldl -o my_test
查看h264文件
xxxxxxxxxxkidwjb@dshanpi-a1:~/sourceCode/videoSourceCode/mppSourceCode/my_mpp$ ffprobe -v quiet -show_streams output.h264[STREAM]index=0codec_name=h264codec_long_name=H.264 / AVC / MPEG-4 AVC / MPEG-4 part 10profile=Maincodec_type=videocodec_tag_string=[0][0][0][0]codec_tag=0x0000width=800height=600coded_width=800coded_height=600closed_captions=0film_grain=0has_b_frames=0sample_aspect_ratio=N/Adisplay_aspect_ratio=N/Apix_fmt=yuv420plevel=40color_range=unknowncolor_space=unknowncolor_transfer=unknowncolor_primaries=unknownchroma_location=leftfield_order=progressiverefs=1is_avc=falsenal_length_size=0id=N/Ar_frame_rate=60/1avg_frame_rate=25/1time_base=1/1200000start_pts=N/Astart_time=N/Aduration_ts=N/Aduration=N/Abit_rate=N/Amax_bit_rate=N/Abits_per_raw_sample=8nb_frames=N/Anb_read_frames=N/Anb_read_packets=N/Aextradata_size=37DISPOSITION:default=0DISPOSITION:dub=0DISPOSITION:original=0DISPOSITION:comment=0DISPOSITION:lyrics=0DISPOSITION:karaoke=0DISPOSITION:forced=0DISPOSITION:hearing_impaired=0DISPOSITION:visual_impaired=0DISPOSITION:clean_effects=0DISPOSITION:attached_pic=0DISPOSITION:timed_thumbnails=0DISPOSITION:non_diegetic=0DISPOSITION:captions=0DISPOSITION:descriptions=0DISPOSITION:metadata=0DISPOSITION:dependent=0DISPOSITION:still_image=0[/STREAM]kidwjb@dshanpi-a1:~/sourceCode/videoSourceCode/mppSourceCode/my_mpp$kidwjb@dshanpi-a1:~/sourceCode/videoSourceCode/mppSourceCode/my_mpp$ ls -l output.h264-rw-rw-r-- 1 kidwjb kidwjb 1085039 10月 31 19:57 output.h264kidwjb@dshanpi-a1:~/sourceCode/videoSourceCode/mppSourceCode/my_mpp$ hexdump -C output.h264 | head00000000 00 00 00 01 67 4d 40 28 8d 8d 50 64 09 af 2c 20 |....gM@(..Pd.., |00000010 00 00 03 00 20 00 00 07 91 e1 00 85 40 00 00 00 |.... .......@...|00000020 01 68 ee 31 b2 00 00 00 01 06 05 6a 3d 07 6d 45 |.h.1.......j=.mE|00000030 73 0f 41 a8 b1 c4 25 d7 97 6b f1 ac 39 30 63 32 |s.A...%..k..90c2|00000040 30 35 63 61 20 61 75 74 68 6f 72 3a 20 41 6c 65 |05ca author: Ale|00000050 78 61 6e 64 65 72 20 4b 6f 76 61 6c 20 32 30 32 |xander Koval 202|00000060 35 2d 30 38 2d 32 35 20 66 69 78 5b 76 64 70 70 |5-08-25 fix[vdpp|00000070 5d 20 46 69 78 20 62 75 69 6c 64 69 6e 67 20 74 |] Fix building t|00000080 65 73 74 73 20 61 67 61 69 6e 73 74 20 6d 75 73 |ests against mus|00000090 6c 20 6c 69 62 63 80 00 00 00 01 06 05 50 d7 dc |l libc.......P..|内存对齐
xxxxxxxxxx//16字节内存对齐Rockchip 的视频编解码硬件(如 VPU / RGA / ISP)通常要求图像数据在内存中的 水平 stride(行跨度)和垂直1.stride(帧高度)必须按特定字节对齐(例如 16 字节或 64 字节),原因包括:
- DMA 传输效率:硬件 DMA 控制器通常以固定块大小读取内存,非对齐会导致额外处理甚至错误。
- 内部缓存行对齐:避免跨缓存行访问,提升带宽和性能。
- 像素格式打包限制:例如 YUV420SP(NV12)格式中,Y 平面每行宽度需对齐,UV 平面也依赖 Y 的对齐。
在 RK3576 等 Rockchip SoC 上,MPP 驱动明确要求hor_stride和 ver_stride至少 16 字节对齐(有时甚至要求 64 或 256 字节,取决于格式和分辨率)。
2.对齐如何影响 frame_size 计算?
xxxxxxxxxxif (fmt <= MPP_FMT_YUV420SP_VU) mpp_enc_data.frame_size = mpp_enc_data.hor_stride * mpp_enc_data.ver_stride * 3 / 2;这里使用的是 对齐后的stride,而非原始 width/height。这是因为:
- 实际分配的缓冲区必须容纳对齐后的每行数据;
read_image()函数也会按照hor_stride写入数据(可能在行末填充 padding);- 如果不用对齐
stride计算buffer size,会导致缓冲区溢出或图像错位。
3.宏原理简析
xxxxxxxxxx假设a = 16(二进制 10000),则 (a - 1) = 15(01111),~(a-1) = ...11110000。
(x + 15) & ~15:先加 15,再清除低 4 位,实现“向上取整到 16 的倍数”。
因为 当 a 是 2 的幂时,可以用位运算加速:
xxxxxxxxxxa = 16 = 2^4a - 1 = 15 = 0b1111~(a - 1) = ...11110000(低 4 位为 0)
mpp编码代码
设定编码器结构体
编码配置需要使用到很多的变量,为了方便管理使用一个统一的结构体来标识编码器
xxxxxxxxxxstruct MPP_ENC_DATA { //这些主要用于 流程控制和日志/性能统计。 uint32_t frm_eos = 0; //Frame End-Of-Stream 标志 当输入帧结束时设为 1,通知编码器不再有新帧。 uint32_t pkt_eos = 0; //Frame End-Of-Stream 标志(本代码未使用) 当输入帧结束时设为 1,通知编码器不再有新帧。 uint32_t frame_count = 0; //已成功编码的帧数,用于统计和调试。 uint64_t stream_size = 0; //已写入输出文件的总字节数(即码流大小),可用于计算平均码率。 //MPP 核心上下文与接口,这些是 MPP 编码器运行所必需的核心资源。 MppCtx ctx = nullptr; //MPP 编码器的上下文句柄,由mpp_create()创建,代表一个编码会话。 MppApi *mpi = nullptr; //指向 MPP API 函数表的指针,通过它调用encode_put_frame()、encode_get_packet()等方法。 MppBuffer frm_buf = nullptr; //用于存放原始 YUV 帧数据的硬件缓冲区(DMA-BUF 或系统内存),由 MPP 分配管理。 MppEncSeiMode sei_mode = MPP_ENC_SEI_MODE_ONE_FRAME;//控制是否插入SEI(Supplemental Enhancement Information)信息,如时间戳、用户数据等。 //MPP_ENC_SEI_MODE_ONE_FRAME表示每帧可带 SEI。 //图像格式与尺寸参数,这些决定了输入数据如何被解释和处理,必须与实际 YUV 文件格式一致。 uint32_t width = 0;//视频的逻辑分辨率(如 1920×1080),即实际图像内容大小。 uint32_t height = 0; uint32_t hor_stride = 0; //水平步长(行对齐宽度),通常是MPP_ALIGN(width, 16),满足硬件 DMA 对齐要求。 uint32_t ver_stride = 0; //垂直步长(帧对齐高度),通常是MPP_ALIGN(height, 16),影响 UV 平面起始位置。 MppFrameFormat fmt = MPP_FMT_YUV420SP; //输入帧的像素格式 MppCodingType type = MPP_VIDEO_CodingAVC; //编码类型 uint32_t num_frames = 0; //unused size_t frame_size = 0; //单帧原始数据所需内存大小(字节) //编码控制参数,这些直接影响编码质量、压缩效率和输出码流特性。 int32_t gop = 60; //GOP(Group of Pictures)长度,即 I 帧间隔。 int32_t fps = 30; //帧率 int32_t bps = 0; //目标码率(Bits Per Second),单位是 bit/s。代码中按width*height/8*fps估算(约 0.125 bps)。 MppEncCfg cfg = nullptr; //编码配置对象,通过mpp_enc_cfg_set_xxx()设置各种参数(分辨率、码率、profile 等),最终传给 MPP。 FILE *fp_output = nullptr; FILE *fp_input = nullptr; //用于 read_image};设定编码器类
对于编码器肯定会有很多操作,将这些操作全部封装成一个类便于管理
xxxxxxxxxxclass Encoder {public: Encoder(char* inputFileName, char* outputFileName, uint32_t width, uint32_t height, MppFrameFormat fmt = MPP_FMT_YUV420SP, MppCodingType type = MPP_VIDEO_CodingAVC, uint32_t fps = 30, uint32_t gop = 60); ~Encoder(); bool encode_all_frames(); // 改为内部循环读取private: MPP_ENC_DATA mpp_enc_data; void init_mpp(); void destroy_mpp();};初始化
mpp_buffer_get
mpp_buffer_get 函数原型:
xxxxxxxxxxMPP_RET mpp_buffer_get(MppBufferGroup group, MppBuffer *buffer, size_t size);- group:
MppBufferGroup类型,表示一个 缓冲区组(buffer pool); - buffer:输出参数,用于返回分配的
MppBuffer句柄; - size:要分配的缓冲区大小(字节)。
1.第一个参数 group 的作用
MppBufferGroup是 MPP 中用于 统一管理一组缓冲区 的对象。你可以:
- 创建一个
buffer group(通过mpp_buffer_group_get()); - 从中分配多个
buffer(mpp_buffer_get(group, ...)); - 最后一次性释放整个
group(mpp_buffer_group_put(group))。
这种方式适合 需要预分配多个 buffer 的场景(如解码器需要 10 个帧缓存)。
2.为什么可以传 NULL?
当你传入group = NULL时,MPP 会:
自动使用一个内部的“默认/匿名”缓冲区组(anonymous group),为你分配一块独立的 buffer。
这意味着:
- 你不需要手动创建和管理
MppBufferGroup; - 分配的 buffer 由 MPP 内部跟踪;
- 你只需在用完后调用
mpp_buffer_put(buffer)即可释放。
- 你不需要手动创建和管理
✅ 适用于“只分配一个 buffer”的简单场景 —— 正如你的代码中只分配一个 frm_buf 用于循环读取 YUV 帧。
MppBufferGroup 在 Rockchip MPP 中的作用 类似于一个内存池(memory pool),但更准确地说,它是一个 缓冲区组(buffer group)管理器,用于统一申请、分配和释放一组具有相同属性的缓冲区
3.为什么说它“相当于内存池”?
(1)通过mpp_buffer_group_get()创建一个 buffer group,指定类型(如 ION、malloc)、对齐、数量等
(2)mpp_buffer_get(group, &buf, size)从 group 中取出一个 buffer
(3)mpp_buffer_group_put(group)一次性释放整个 group 中所有 buffer
(4)MPP 内部可复用 buffer,避免频繁调用malloc/ion_alloc
4.什么时候需要显式使用MppBufferGroup?
当你需要:
- 多帧并行处理(如 pipeline 中同时有 3 帧在编码);
- 零拷贝传递 buffer(如从摄像头 V4L2 直接获取 buffer 给 MPP);
- 严格控制内存生命周期(避免频繁分配/释放);
xxxxxxxxxxMppBufferGroup group;mpp_buffer_group_get(&group, MPP_BUFFER_TYPE_ION, ...);mpp_buffer_get(group, &buf1, size);mpp_buffer_get(group, &buf2, size);// ... 使用 ...mpp_buffer_group_put(group); // 一次性释放所有5.总结
MppBufferGroup ≈ 内存池:用于高效管理多个 buffer;
- 传 NULL = 使用 MPP 内部临时池:适合简单、单 buffer 场景;
- 显式创建 group = 自建内存池:适合高性能、多 buffer 场景。
初始化mpp编码器
mpp_create
用于创建mpp实例,函数原型:
xxxxxxxxxxMPP_RET mpp_create(MppCtx *ctx, MppApi **mpi)MppCtx是提供给⽤⼾使⽤的 MPP 实例上下⽂句柄,⽤于指代解码器或编码器实例MppApi结构体封装了 MPP 的对外 API 接口,⽤⼾通过使⽤MppApi结构中提供的函数指针实现视频编解码功能
mpp_init
用于初始化mpp实例,函数原型:
xxxxxxxxxxMPP_RET mpp_init(MppCtx ctx, MppCtxType type, MppCodingType coding)MppCtx是提供给⽤⼾使⽤的 MPP 实例上下⽂句柄,⽤于指代解码器或编码器实例MppCtxType是一个enum类型,如下:xxxxxxxxxxtypedef enum {MPP_CTX_DEC, /**< decoder */MPP_CTX_ENC, /**< encoder */MPP_CTX_ISP, /**< isp */MPP_CTX_BUTT, /**< undefined */} MppCtxType;MppCodingType是编码类型,这里选的是MPP_VIDEO_CodingAVC
mpp_enc_cfg_init
初始化mpp的配置cfg,函数原型如下:
xxxxxxxxxxMPP_RET mpp_enc_cfg_init(MppEncCfg *cfg)MppEncCfg配置单元
设置cfg
MPP 推荐使⽤封装后的
MppEncCfg结构通过control接口的MPP_ENC_SET_CFG/MPP_ENC_GET_CFG命 令来进⾏编码器信息配置。由于编码器可配置的选项与参数繁多,使⽤固定结构体容易出现接口结构体频繁变化,导致接口⼆进制 兼容性⽆法得到保证,版本管理复杂,极⼤增加维护量。 为了缓解这个问题
MppEncCfg使⽤ (void *) 作为类型,使⽤< 字符串 值 > 进⾏
key map式的配置,函数接口 分为s32/u32/s64/u64/ptr,对应的接口函数分为 set 与 get 两组xxxxxxxxxx//cfg设置mpp_enc_cfg_set_s32(mpp_enc_data.cfg, "prep:width", mpp_enc_data.width);mpp_enc_cfg_set_s32(mpp_enc_data.cfg, "prep:height", mpp_enc_data.height);mpp_enc_cfg_set_s32(mpp_enc_data.cfg, "prep:hor_stride", mpp_enc_data.hor_stride);mpp_enc_cfg_set_s32(mpp_enc_data.cfg, "prep:ver_stride", mpp_enc_data.ver_stride);mpp_enc_cfg_set_s32(mpp_enc_data.cfg, "prep:format", mpp_enc_data.fmt);mpp_enc_data.bps = mpp_enc_data.width * mpp_enc_data.height / 8 * mpp_enc_data.fps;mpp_enc_cfg_set_s32(mpp_enc_data.cfg, "rc:mode", MPP_ENC_RC_MODE_VBR);mpp_enc_cfg_set_s32(mpp_enc_data.cfg, "rc:bps_target", mpp_enc_data.bps);//预期码率mpp_enc_cfg_set_s32(mpp_enc_data.cfg, "rc:bps_max", mpp_enc_data.bps * 17 / 16); //最大接受码率mpp_enc_cfg_set_s32(mpp_enc_data.cfg, "rc:bps_min", mpp_enc_data.bps / 16); //最低接收码率mpp_enc_cfg_set_s32(mpp_enc_data.cfg, "rc:fps_in_flex", 0); //输⼊帧率是否可变的标志位,默认为0mpp_enc_cfg_set_s32(mpp_enc_data.cfg, "rc:fps_in_num", mpp_enc_data.fps);mpp_enc_cfg_set_s32(mpp_enc_data.cfg, "rc:fps_in_denom", 1); // ← 必须 >=1mpp_enc_cfg_set_s32(mpp_enc_data.cfg, "rc:fps_out_flex", 0);//输出帧率是否可变的标志位,默认为0mpp_enc_cfg_set_s32(mpp_enc_data.cfg, "rc:fps_out_num", mpp_enc_data.fps);mpp_enc_cfg_set_s32(mpp_enc_data.cfg, "rc:fps_out_denom", 1); // ← 必须 >=1mpp_enc_cfg_set_s32(mpp_enc_data.cfg, "rc:gop", mpp_enc_data.gop);mpp_enc_cfg_set_s32(mpp_enc_data.cfg, "rc:drop_mode", MPP_ENC_RC_DROP_FRM_DISABLED);//丢帧模式使能mpp_enc_cfg_set_s32(mpp_enc_data.cfg, "codec:type", mpp_enc_data.type);if (mpp_enc_data.type == MPP_VIDEO_CodingAVC) {mpp_enc_cfg_set_s32(mpp_enc_data.cfg, "h264:profile", 77);mpp_enc_cfg_set_s32(mpp_enc_data.cfg, "h264:level", 40);//⼀般配置为level 4.1即可满⾜要求mpp_enc_cfg_set_s32(mpp_enc_data.cfg, "h264:cabac_en", 1);}ret = mpp_enc_data.mpi->control(mpp_enc_data.ctx, MPP_ENC_SET_CFG, mpp_enc_data.cfg);if (ret) goto FAIL;设置SEI
xxxxxxxxxxmpp_enc_data.sei_mode = MPP_ENC_SEI_MODE_ONE_FRAME;mpp_enc_data.mpi->control(mpp_enc_data.ctx, MPP_ENC_SET_SEI_CFG, &mpp_enc_data.sei_mode);获取SPS/PPS
SPS/PPS 是解码必需的元数据 播放器或解码器必须先读到 SPS/PPS,才能正确解析后续的 I/P/B 帧。如果它们被“延迟写入”甚至因程序崩溃而丢失,生成的视频文件将无法播放。
xxxxxxxxxxif (mpp_enc_data.type == MPP_VIDEO_CodingAVC) {MppPacket packet = NULL;ret = mpp_enc_data.mpi->control(mpp_enc_data.ctx, MPP_ENC_GET_EXTRA_INFO, &packet);if (ret == MPP_OK && packet) {void *ptr = mpp_packet_get_pos(packet);size_t len = mpp_packet_get_length(packet);if (mpp_enc_data.fp_output && ptr && len > 0) {fwrite(ptr, 1, len, mpp_enc_data.fp_output);fflush(mpp_enc_data.fp_output);//强制将SPS/PPS立即写入文件(不缓冲)}mpp_packet_deinit(&packet);}}
进行编码
CPU与硬件同步
在 Rockchip MPP(Media Process Platform)中,mpp_buffer_sync_begin() 和 mpp_buffer_sync_end() 是用于 CPU 与硬件(如 VPU、GPU、DMA 引擎)之间内存同步的关键函数,尤其在使用 物理连续内存(如通过 libdrm 或 ION 分配的 buffer) 时非常重要。
在 RK3576 这类 SoC 上,MPP 使用的帧缓冲区(frm_buf)通常分配在 DMA 可访问的物理内存中(例如通过 rk_mpi 内部的 MppBuffer 机制)。这类内存可能被:
- CPU 读写(比如你调用
read_image把 YUV 数据写入 buffer), - VPU(视频编解码硬件) 读取(编码器从该 buffer 读取原始帧)。
而 CPU 和 VPU 通常有各自的缓存(Cache)或内存视图。如果不做同步:
CPU 写入的数据可能还停留在 CPU 缓存(Cache) 中,VPU 读到的是旧数据或垃圾;
或者 VPU 写入的数据(如解码输出)CPU 读不到最新内容。
这就需要 显式内存同步(Cache Coherency Management)。
xxxxxxxxxxvoid *buf = mpp_buffer_get_ptr(mpp_enc_data.frm_buf); mpp_buffer_sync_begin(mpp_enc_data.frm_buf);//开始同步 ret = read_image((uint8_t *)buf, mpp_enc_data.fp_input, mpp_enc_data.width, mpp_enc_data.height, mpp_enc_data.hor_stride, mpp_enc_data.ver_stride, mpp_enc_data.fmt); mpp_buffer_sync_end(mpp_enc_data.frm_buf);//结束同步 if (ret != MPP_OK || feof(mpp_enc_data.fp_input)) { mpp_enc_data.frm_eos = 1; break; }帧编码
零拷贝
“零拷贝”(Zero-copy)是指:
原始图像数据从源头(如摄像头、GPU 渲染输出、DMA 采集)到编码器,全程不经过 CPU 内存拷贝。
实现方式:
使用
物理连续、DMA 可访问的内存如:
- ION buffer
- DMA-BUF
- DRM PRIME buffer(常用于 GPU/V4L2 交互)
这些 buffer 由内核或专用内存分配器创建,硬件(VPU、ISP、GPU)可直接读写。
MPP 的
MppBuffer就是对这类内存的封装。
优势: ✅ 无 CPU 拷贝开销 ✅ 无 cache 同步开销(或由硬件自动处理) ✅ 低延迟、高吞吐,适合 4K/60fps 等高性能场景
encode_put_frame
xxxxxxxxxxMPP_RET encode_put_frame(MppCtx ctx, MppFrame frame)- ctx : MPP 解码器实例
- frame :待输⼊的图像数据
- 输⼊ frame 图像数据给 ctx 指定的 MPP 编码器实例
由于编码器的输⼊图像⼀般都⽐较⼤,如果进⾏拷⻉,效率会⼤幅度下降,所以编码器的输⼊函数需要 等待编码器硬件完成对输⼊图像内存的使⽤,才能把输⼊函数返回,把使⽤后的图像归还给调⽤者。基于以上的考虑,
encode_put_frame是阻塞式函数,会把调⽤者阻塞住,直到输⼊图像使⽤完成,会⼀定程 度上导致软硬件运⾏⽆法并⾏,效率下降。encode_get_packet
xxxxxxxxxxMPP_RET encode_get_packet(MppCtx ctx, MppPacket *packet)- ctx : MPP 解码器实例
- packet :⽤于获取
MppPacket实例的指针 - 从 ctx 指定的 MPP 编码器实例⾥获取完成编码的 packet 描述信息。
(1)取头信息与图像数据
以 H.264 编码器为例,编码器的输出数据分为头信息( sps/pps )和图像数据( I/P slice )两部分,头信息 需要通过 control 接口的
MPP_ENC_GET_EXTRA_INFO命令获取,图像数据则是通过encode_get_packet接口来获取。(2) H.264 编码器输出码流的格式
⽬前硬件固定输出带
00 00 00 01起始码的码流,所以encode_get_packet函数获取到码流都是带有00 00 00 01起始码。如果需要去掉起始码,可以从起始码之后的地址进⾏拷⻉。(3)码流数据的零拷⻉
由于使⽤
encode_put_frame和encode_get_packet接口时没有提供配置输出缓存的⽅法,所以使⽤encode_get_packet时⼀定会进⾏⼀次拷⻉。⼀般来说,编码器的输出码流相对于输⼊图像不算⼤,数据 拷⻉可以接受。如果需要使⽤零拷⻉的接口,需要使⽤enqueue/dequeue接口以及MppTask结构。
xxxxxxxxxx MppFrame frame = nullptr; mpp_frame_init(&frame); mpp_frame_set_width(frame,mpp_enc_data.width); mpp_frame_set_height(frame,mpp_enc_data.height); mpp_frame_set_hor_stride(frame,mpp_enc_data.hor_stride); mpp_frame_set_ver_stride(frame,mpp_enc_data.ver_stride); mpp_frame_set_fmt(frame,mpp_enc_data.fmt); mpp_frame_set_buffer(frame,mpp_enc_data.frm_buf); mpp_frame_set_eos(frame,mpp_enc_data.frm_eos); ret = mpp_enc_data.mpi->encode_put_frame(mpp_enc_data.ctx,frame); mpp_frame_deinit(&frame); if(ret) return false; MppPacket packet = nullptr; ret = mpp_enc_data.mpi->encode_get_packet(mpp_enc_data.ctx,&packet); if(ret) return false;获取码流写入文件
xxxxxxxxxxif (packet) { void *ptr = mpp_packet_get_pos(packet); size_t len = mpp_packet_get_length(packet); if (mpp_enc_data.fp_output && ptr && len > 0) { fwrite(ptr, 1, len, mpp_enc_data.fp_output); } mpp_enc_data.stream_size += len; mpp_enc_data.frame_count++; mpp_packet_deinit(&packet); }将编码器生成的一帧压缩数据(如 H.264/H.265 码流)写入到文件(如 .h264)中,用于后续播放、存储或传输。
mpp_packet_get_pos(packet)中的pos是什么?pos(position)指的是:码流数据在内存中的起始地址(虚拟地址)pos表示“当前有效数据的起始位置”,因为 packet 内部可能有预留头部或对齐空间,有效负载不一定从 buffer 起始处开始。
结束编码
xxxxxxxxxx// Send EOS and drain MppFrame eos_frame = nullptr; mpp_frame_init(&eos_frame); mpp_frame_set_eos(eos_frame, 1); mpp_enc_data.mpi->encode_put_frame(mpp_enc_data.ctx, eos_frame); mpp_frame_deinit(&eos_frame); MppPacket packet = nullptr; while (mpp_enc_data.mpi->encode_get_packet(mpp_enc_data.ctx, &packet) == MPP_OK && packet) { void *ptr = mpp_packet_get_pos(packet); size_t len = mpp_packet_get_length(packet); if (mpp_enc_data.fp_output && ptr && len > 0) { fwrite(ptr, 1, len, mpp_enc_data.fp_output); } mpp_packet_deinit(&packet); }这段代码的作用是:向 MPP 编码器发送“流结束”(End-of-Stream, EOS)信号,并清空编码器内部可能缓存的剩余编码帧(如 B 帧、延迟帧),确保所有已编码的数据都被完整输出。
为什么需要 EOS?
MPP 编码器(尤其是 H.264/H.265)在编码过程中可能会:
缓存帧:为了 B 帧参考、码率控制(VBV)、帧重排序(如低延迟关闭时);
延迟输出:最后一帧输入后,可能还有 1~3 帧未输出。
如果不显式通知“输入结束”,编码器不知道你已经停止送帧,可能不会 flush 出剩余数据,导致:
视频文件缺少最后几帧;
播放时突然截断;
码流不完整,无法正确解析。
构造一个 EOS 帧
xxxxxxxxxxmpp_frame_set_eos(eos_frame, 1); // 标记为 EOS 帧- 这个
eos_frame不包含图像数据,只是一个控制信号; mpp_frame_set_eos(eos_frame, 1)表示:“输入流到此结束”;- 调用
encode_put_frame将这个信号送入编码器。
- 这个